Scenario
We recently had a project that started as a National Retailer wanted to pilot Google’s Local Inventory Advertising (LIA) program. The Advertising program bridges the online and offline world. The retailer, which has 500+ stores nationwide, could advertise products that are in stock locally. If you search for “Bauer Excaliber hockey skates” you would not only get an advertisement from the retailer but also if it’s schema.org/InStock at a location and distance to that store. It’s a powerful conversion opportunity, exploiting the retailer’s vast network of store and inventory, consumers get actionable information to go pick it up physically.
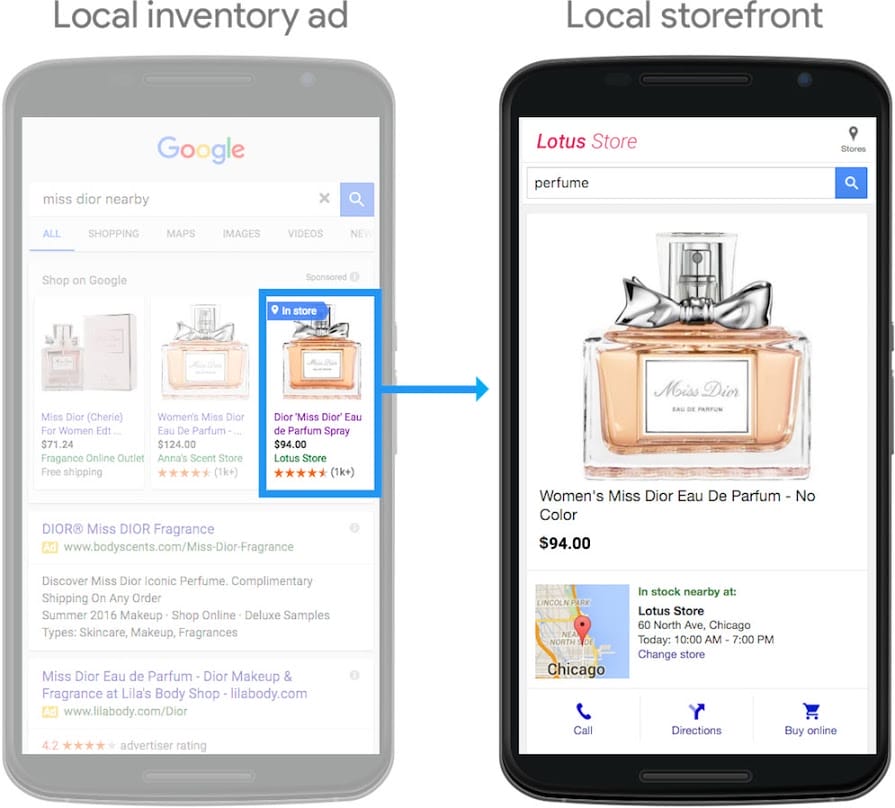
Part of the conditions to LIA program is to have Schema.org data on Product detail pages at a level that details the availability in each store. For each schema.org/Product and its schema.org/ProductModel, we need to expose their schema.org/Offer and its schema.org/availableAtOrFrom StoreID.
Approaches considered
Like many large businesses, the Marketing team has numerous initiatives dependent on IT for delivery. They had an aggressive timeline, 8-10 weeks, when started we provided them several schema.org at scale options to consider. To maximize the number of data consumers of schema.org data we wanted to render the schema.org data server side, so that it is available in the HTML Document Object Model on page load.
- Custom Programming: Typically this meant encoding data into the Product Detail Page template, using either Microdata or JSON-LD This approach, however, relies heavily on the IT team which couldn’t meet the aggressive schedule due to other commitments.
- Bulk Data Transformation: Our next best option was to implement a bulk data transformation, which would take the same Google AdWords Feed and supplement with BazaarVoice review data.
- Javascript Rendering: The third approach is to implement Javascript which builds the JSON-LD dynamically after page load.
Ultimately, we chose #3 Javascript Rending because it involved no IT, it could meet the LIA requirements for Google in a short time and the data/code remained within the control of the Business.
Problems with SDTT & GTM Datalayer
The initial implementation by the team was to provide schema.org data mapped from Google Tag Manager Datalayer variables. The data layer had Product Information, Offers for different skus for the selected store and the BazaarVoice review data (AggregateRating). The only catch was, this data while convenient was only available after 5-10 seconds because of all the Javascript on the page to prepare the data. To add complexity, the retailer has different pricing for different stores. For example, Rural stores which incur more shipping costs could have higher prices than urban centers. Therefore, on each page load needs to first geolocate the user and suggest the closest store, before the prices could be shown. Similarly, BazaarVoices elements loads using Javascript and its data is loaded after a few seconds as well.
When we tested the schema.org data, we found the <script type=”application/ld+json”> when we inspected the HTML. However, when we tested with Google’s Structured Data Testing Tool, the tool which does a good job processing Javascript, simply cut off the page after several seconds of Javascript processing and wouldn’t show the data.
The Additive Experiment method
We set up a workshop to go through step-by-step, testing the limits of what could be done. The relevant Product information was spread throughout the webpage, so we wanted to explore the extent of what was possible. In order for this to be successful, we relied heavily on the Google’s ability to reconcile JSON-LD data by its @id values. For example, given the two sample JSON-LD inputs below:
{
"@context": "http://schema.org/",
"@type”: "Product",
"@id": "#product",
"name": "Blue Widget"
}
{
"@context": "http://schema.org/",
"@type": "Product",
"@id": "#product",
"image": "http://cdn.amazon.com/TheEnterprise/product_blue_widget.jpeg"
}
Would be reconciled by Google as:
{
"@context": "http://schema.org/",
"@type": "Product",
"@id": "#product",
"name":"Blue Widget",
"image": "http://cdn.amazon.com/TheEnterprise/product_blue_widget.jpeg"
}
Therefore, we would deconstruct the data into logical parts, then the additive data elements available to SDTT at the time it cuts off would show the problematic data by whats not shown. The first element, Basic Product Data that’s available in the HTML DOM that comes from the server before any Javascript. When viewing a webpage, if you right-click and View Page Source, that HTML is what comes from the server. This is data which is immediately available to Javascript for parsing and could be published immediately. There, we found Product Name, one image in the meta og:image, the Product Description. We coded some Javascript selectors, e.g. document.querySelector, to build out a basic Product schema JSON-LD data block. As an example, to get the Product Image URL:
document.querySelector('meta[property="og:image"]')
We implemented this as a GTM Tag that triggers on DOM Ready and Published, ready for our first live test.
Testing & Validation
When testing on Google we found the data was being discovered.
{
"@context": "http://schema.org/",
"@type": "Product",
"@id": "#product",
"name": "Blue Widget",
"description": "Lots of great features!",
"image": "http://cdn.amazon.com/TheEnterprise/product_blue_widget.jpeg"
}
While it was a good first test step, we were still missing necessary aspects, including Offers and Reviews. The next attempt we made was to retrieve Offers. We looked backward from the data layer, to see how it was populated. We discover a Custom Javascript Event that published the Offers once a Store was select. We setup the trigger and once we found the pricing and availability information we were able to add the Offer. We appended this JSON-LD data block by referring back to the #product defined earlier and use the additive information.
{
"@context": "http://schema.org/",
"@type" :"Product",
"@id": "#product",
"offers": {
"@type": "Offer",
"price": 45.00,
"priceCurrency": "USD",
"availability": "InStock"
}
}
If the store is selected, we could include the schema.org/availableAtOrFrom: “StoreID123”. This StoreID has to match those in the Google Business Profile (GBP) account. These are unique identifiers the Retailer assigns to them and reused for LIA and in schema.org markup.
This Offer data works great for Product with no variants or when for Multi-variant Products whose ProductModel (sku) is selected. In scenarios in which a Product has multiple variants / skus, instead of Offer we would show AggregateOffer with a lowPrice.
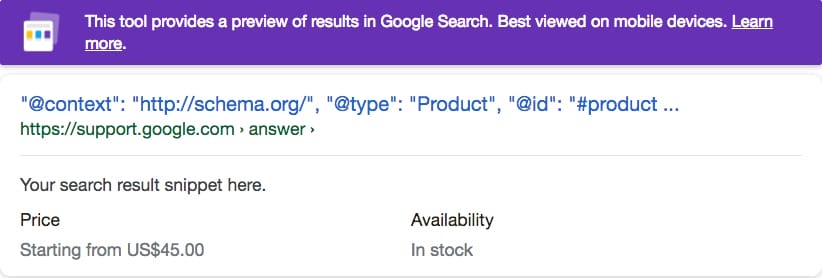
When testing this data block, we were less certain that the data would be available in time for the Javascript rendering for the SDTT. In this test it was available and the data automatically merged into the earlier data block.
Next, we wanted to get the BazaarVoice data for AggregateReting data. We found the Javascript code that loads BazaarVoice and looked for a way to hook into the function. Being that the BazaarVoice Javascript was included in the Page Load DOM, our GTM tag is loaded too late to mutate the Javascript function. We instead attached a Javascript onChange listener to the DIV Review element. When that changes, we would get the rating count and rating value data from DOM elements innerHTML. We could then emit a third JSON-LD data block and tie in with the earlier data using the same @id : “#product”
{
"@context": "http://schema.org/",
"@type": "Product",
"@id": "#product",
"aggregateRating": {
"@type": "AggregateRating",
"ratingCount": 12,
"ratingValue": 4.6
}
}
When we published the tags and ran it through Google, the data was available in time and Google rendered the compiled JSON-LD data blocks. The Testing Tool also showed us the Preview button and Product rich result. Had the Javascript had too many delays and didn’t make the cutoff, we knew which was data source was the culprit. A decision would be made whether to include what was discoverable. The data that doesn’t show, we would revisit the Javascript event model to discover alternative methods.
SDTT != Search Console Report. In our experience, if you find schema data is shown in the Structured Data Testing Tool you will find it in the Search Console Structured Data report after 3-5 days (unless its a large site and the pages haven’t yet been reindexed). The opposite, however, isn’t always true. There have been times where we have not seen data in the SDTT but we do find the data in the Search Console. So, even if we’re at wit’s end trying to get the data to show in Search Console, I would leave the GTM Tag in place until we confirm the Search Console report.
Future Work
I really like the additive capability of composing schema.org markup data block by data block. Sometimes all the information isn’t available at runtime and to meet the needs of an early adopter you need to experiment to make it work. In the future, our work with the client will involve adding How-To Videos, cross-sell products, upsell products, related links, additional images all using the additive method.
Of course, this is all great for the retailer, they now receive Google rich snippets and LIA in time for the holiday shopping season. For other schema.org consumers, however, we are less fortunate as they less often support handle Javascript rendering like Google does. For these other consumers we need to include the data from the Server as part of the HTML sent back to the client. This is a business decision, however, what is the additional cost of the IT project to implement weighed against the provable ROI of supporting other data consumers.
If you need a hand getting started with your structured data strategy, we’ve helped customers such as SAP and Keen Footwear drive more quality search traffic to their websites.
Start reaching your online business goals with structured data.

Mark van Berkel is the Chief Technology Officer and Co-founder of Schema App. A veteran in semantic technologies, Mark has a Master of Engineering – Industrial Information Engineering from the University of Toronto, where he helped build a semantic technology application for SAP Research Labs. Today, he dedicates his time to developing products and solutions that allow enterprise teams to leverage Schema Markup to boost their AI strategy and drive results.