According to Google, an entity refers to a single, unique, well-defined, and distinguishable thing or idea.
Entities can be diverse, ranging from tangible elements like people, organizations, and products to abstract concepts and creative works. They possess defining characteristics or attributes, like size, colour, and duration. And most importantly, entities exist in relation to other things/entities.
Take, for example, “xylopental”. This is a string of characters that have no meaning to humans and, therefore, have no meaning to machines. However, if I invented a new musical instrument named “Xylopental,” this string of letters would become an identifiable entity. It is understood in relation to musical instruments, which is also an entity.
Entities need to be described in relation to other entities to have any meaning.
In its information architecture, Google often refers to entities as “topics.” From a content perspective, we can consider entities in SEO as topics within your content that become well-defined by referencing other related things.
Entities and their connections are crucial in developing Google’s Knowledge Graph. Google’s Knowledge Graph is a database that Google uses to quickly retrieve information about specific topics or entities. Any information Google has on a particular entity will show up in the Knowledge Panel, as shown below.
For example, when we search for “Berkshire Hathaway” on Google, we get a knowledge panel that conveys information about Berkshire Hathaway’s owner, stock prices, revenue, and more.
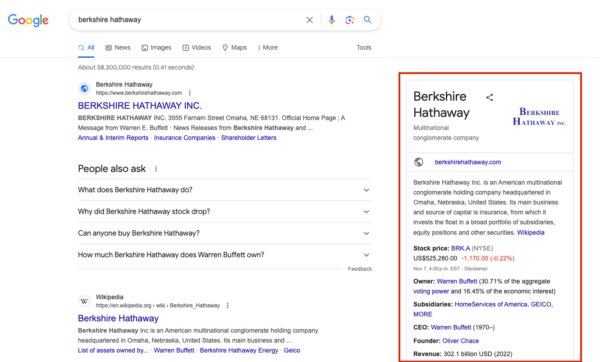
In the “People also ask” section, we can see queries that don’t specifically name Berkshire Hathaway, like “Does Buffett own McDonald’s?”

As the long-time owner and CEO of Berkshire Hathaway, Warren Buffett is often synonymous with his brand. McDonald’s is Buffett’s favorite breakfast meal, and he had previously purchased 4.3% of McDonald’s stocks but sold it in 1999.
This explains the inclusion of the question “Does Buffett own McDonald’s?” even though it doesn’t mention Berkshire Hathaway at all. All this information is derived through context from entities that are related to one another.
What is the Difference Between Entities and Keywords?
A common misconception SEOs have is that entities are just like keywords. Keywords are words or phrases that searchers use in their search queries. It can be a single word, a phrase, a sentence or a question. Historically, search engines would rank pages on the SERP using keyword matching.
However, the method of lexical search presented a few challenges.
- Keywords tend to be ambiguous because certain words can have multiple meanings. For example, the word ‘Java’ can refer to either the programming language or the island of Indonesia.
- Different languages tend to phrase the same things differently. For example, the term ‘rebord de fenêtre’ in French translates directly to ‘edge of window’ in English. But it is actually referring to a windowsill.
As a result, the old search algorithms were producing less relevant and accurate results for searchers.
Entities, on the other hand, are universally understood concepts that are not bounded by language or ambiguity. They are broader topics that keywords can stem from. They are distinguishable, especially through their relation to other things. Unlike keywords, entities have an additional layer of context, which can provide greater clarity to search engines.
How do Entities Relate to SEO?
Search engines are evolving toward a more semantic approach, analyzing the concepts and meanings within user queries. They identify relevant pages that answer the entities in question with greater context and accuracy.
As search engines advance in their understanding, there is inevitable demand for SEO strategies to also become more semantic to better align with this sophisticated and nuanced way of search. The good news is that you can assist search engines in grasping the entities and context of the content on your site.
Your website serves as the information hub about things related to your organization. The services provided by your organization, your postal address, your customer reviews, your blog articles – these are all entities related to your organization.
However, the content often exists in the form of plain text, images, videos and infographics. Humans can consume this form of information but machines and search engines cannot comprehend information in this unstructured manner.
Creating Machine-Readable Content
To bridge this gap between human understanding and machine interpretation, implementing semantic Schema Markup to define, describe and connect your entities is crucial. By meticulously defining entities within your content, you are essentially structuring your data in a format that search engines and machines can understand.
You can also further define the entities on your site by linking them to other linked entities in external authoritative databases like Google’s Knowledge Graph, Wikipedia, or Wikidata. This helps search engines disambiguate the entities on your page.
Defining these entities ensures your content is contextually understood by machines. This contextual understanding allows search engines to display your content for a broader range of relevant queries, expanding your site’s visibility and attracting a more qualified audience.
If you leave AI search engines to their own devices without informing them about the entities on your site, you are leaving it to them to decide on what is “true” for your content. You can control how machines interpret your content by defining your entities to prevent hallucinations and inaccuracies from being presented about your organization. This strategic approach safeguards your organization’s E-E-A-T and credibility.
So, now you know why you should define your entities, but how do you do it?
How to Identify and Define Page Entities
Author and Deploy Schema Markup
To have your content topics recognized as entities by search engines, use the Schema.org vocabulary to structure your data. You can use the Schema.org Types and properties to describe the entities across your site.
Many organizations tend to use a Schema Markup plugin to automate their Schema Markup process. However, many of these plugins will only markup certain page Types or properties. As such, you cannot customize your markup to properly define your entities or link them to other entities on your site.
If you want to provide search engines with a clear understanding of your content, you need to describe your entities thoroughly and leverage as many relevant properties as possible. The Schema App Editor and Highlighter are two great options if you want to implement custom semantic Schema Markup on your site.
Add Unique Identifiers to Schema Markup
For your entity to be identifiable and retrievable, it must have a distinct Uniform Resource Identifier (URI). URIs can help machines identify unique resources (like entities) and enable data interlinking.
In JSON-LD, this is expressed with the ‘@id’ attribute. By adding the ‘@id’ attribute to the entities in your Schema Markup, you can easily connect and refer back to other entities on your site so that search engines can clearly understand the relationship between different entities on your site.
For example, the author page for Mark van Berkel contains all the information about the person Mark van Berkel. Therefore, we can use Person markup on that page and define the entity ‘Mark van Berkel’ using the Schema.org properties. When we create the markup, we can add an ‘@id’ so that any connections to Mark can be indicated using the @id.

Search engines like Google can still read and qualify your page for a rich result if you don’t include an @id for your entities. However, you wouldn’t be able to connect the entities on your site in a machine-readable manner.
When you publish your Schema Markup using the Schema App Highlighter or Editor, our tool automatically generates HTTPs URIs for the entities defined in your Schema Markup.
Connect Your Entities
Connecting these entities on your website to explain how they are related, and extending these connections to external knowledge graphs, such as Google’s Knowledge Graph, Wikipedia, or Wikidata, helps search engines to disambiguate the entities on your site.
For example, Mark is one of the founders of the organization Schema App. We can leverage the ‘founder’ property under the Organization type to express that Mark is the founder of Schema App. And since we’ve already defined the entity Mark on his author page, we can link the entity ‘Mark’ using his @id to the entity ‘Schema App’ in the Organization markup.

That way, search engines know that this specific entity, Mark van Berkel, which is described on this page (https://www.schemaapp.com/author/vberkel/#Person), is the founder of Schema App.
As mentioned earlier, you can also connect your entities to external knowledge graphs to distinguish the entities on your site. External knowledge graphs are authoritative databases comprising millions of entities and their relationships. These entities link to other entities across the web which is why they are referred to as “linked entities”.
The linked entities identified in these external knowledge graphs also have unique identifiers, enabling connections to your own entities.
For example, Vancouver is the name of a city in British Columbia, Canada and also the name of a city in Washington State, US.
If your organization is a restaurant based in Vancouver, BC, you can describe your organization’s areaServed property by linking it to the right entity on:
- Google’s knowledge graph (/m/080h2), OR
- Wikipedia (https://en.wikipedia.org/wiki/Vancouver), OR
- Wikidata (https://www.wikidata.org/wiki/Q24639).
That way, search engines can clearly understand which Vancouver you’re referring to.
By establishing these relationships, you empower machines not only to comprehend existing information deeply but also to infer new knowledge based on this contextual understanding.
How do Entities Relate to Knowledge Graphs?
This process of defining and connecting entities effectively constructs a robust knowledge graph for your organization, providing a comprehensive and accurate representation of your content from a digital scope. Entities serve as the foundational building blocks of information that knowledge graphs organize into explicit relationships.
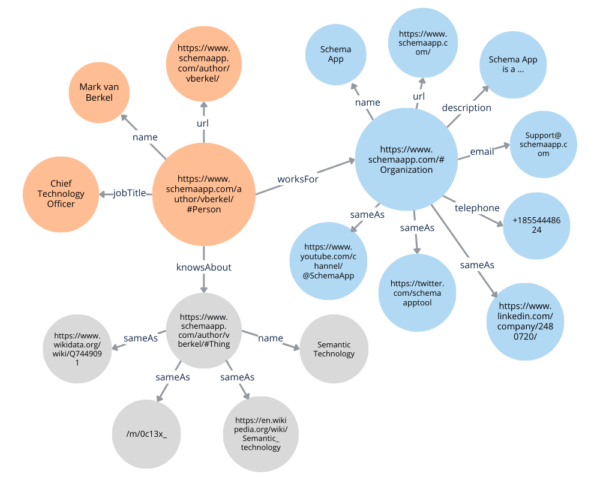
By capturing these complex relationships between entities and building context, knowledge graphs provide machines with a robust understanding of how different entities are related. Linking your entities internally and externally enriches the information available to search engines to create a holistic view of your organization.
This approach also helps prevent misrepresentation of your content and avoids machine confusion between ambiguous entities. Consider the thing, “Apple”, as an example; it could refer to the fruit or the brand. By linking your entity to the relevant external definition using the sameAs property, you offer an explicit distinction and enable search engines to align your content accurately with user queries.
Learn the fundamentals of Content Knowledge Graphs and actionable steps to develop your own using Schema Markup.
Schema App Helps Define Your Entities & Develop Your Knowledge Graph
You can help search engines further understand, contextualize and distinguish the entities on your site using Schema Markup. If you are looking to leverage semantic Schema Markup to define your entities and develop a robust content knowledge graph for your organization, we can help.
At Schema App, we help enterprise SEO teams leverage semantic Schema Markup to define and link their entities, develop their knowledge graph, and improve search performance. Visit our website to learn more about our Schema Markup and knowledge graph solution.
Curious about how we can support your organization? Fill out this form to get started and connect with us.

Andrea Badder is the Digital Marketing Specialist at Schema App. She specializes in SEO and develops educational resources to help marketing teams understand the value of Schema Markup and Content Knowledge Graphs for semantic search, content strategy, and AI-driven initiatives. Prior to joining Schema App, Andrea worked as a brand strategist and copywriter at a marketing agency. She is also a graduate from the University of Guelph.