At Schema App, we take pride in our expertise and extensive experience in harnessing the power of semantics. Led by our co-founder, Mark van Berkel, who possesses over a decade of invaluable knowledge in semantic technology, and supported by a team with a combined experience of over 60 years in this field, we confidently identify ourselves as a leading Semantic Technology company.
Since our inception, we’ve been helping organizations across the globe implement connected Schema Markup on their websites to strengthen their SEO strategy.
By implementing Schema Markup, our customers can achieve rich results on search engine results pages (SERPs) and increase traffic to their sites. However, the advantages of Schema Markup extend beyond just obtaining rich results. Schema Markup is a semantic technology with numerous benefits.
In this article, we will explore what semantic technology is and how Schema App leverages it to provide meaningful context and understanding of data.
Understanding Semantic Technology
Semantic technology is a set of technologies, methodologies and standards that provide meaning (semantics) to data. It achieves this by representing relationships between different categories of entities, transforming raw data into knowledge.
By providing context, semantic technology enables machines to better comprehend and interpret data, leading to more intelligent decision-making processes.
Background and Terminology
Before jumping into how Schema App is semantic, it is essential to familiarize ourselves with key terms in the field of semantic technology.
Here is a glossary of terms that will be referenced throughout this article.
RDF (Resource Description Framework)
A framework used to express data as a directed graph using subject-predicate-object statements known as triples.
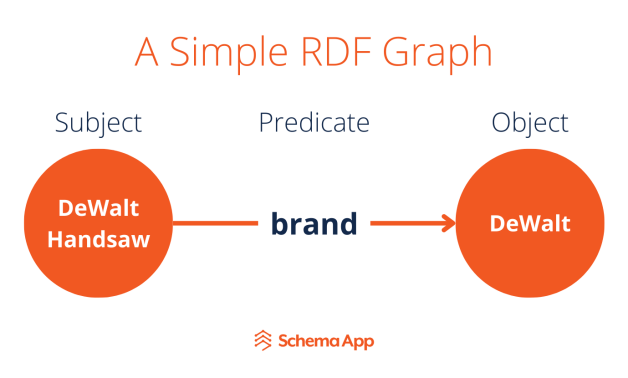
By combining these triples, vast interconnected graphs of resources can be created. This is done using Uniform Resource Identifiers (URIs).
Uniform Resource Identifier (URI)
A URI is a string of characters that identifies a resource. It provides a consistent way to identify resources across different systems and protocols.
A URL is a string of characters that both identifies a resource and where it’s located on the web. Therefore, a URL is a type of URI.
JavaScript Object Notation for Linked Data (JSON-LD)
JSON-LD is a serialization format for expressing RDF data. In simple terms, it’s one way to describe the subject-predicate-object statements. It also happens to be Google’s preferred format for consuming Schema Markup/structured data.
Ontology
An ontology defines the types of entities that can exist within a dataset, and the properties that describe and connect these entities. Schema.org is an example of a loose ontology, serving as a vocabulary rather than imposing strict logic constraints like other formal ontologies.
Knowledge Graph
A knowledge graph is a structured representation of information that captures the context and connections between entities, their attributes, and the relationships between them.
Schema App uses JSON-LD to express how the Schema.org “ontology” defines the connections in your data (in our case, your content).
As a result, content on your page that states things like “this DeWalt Handsaw is from the brand DeWalt” and you can express that in JSON-LD to help search engines understand that statement.

When you connect multiple entities using these technologies, you are constructing a knowledge graph.
Search engines can then interpret the relationships between entities through these knowledge graph connections, enhancing their understanding of the content on your site. More recently, knowledge graphs are also being explored as a means of grounding LLMs to prevent hallucinations in Generative AI.
So as you can see, these technologies are powerful sources of meaning (semantics) for machines like search engines.
The most foundational resource that both uses and is, in itself, a semantic technology, is Schema.org. Schema App utilizes the Schema.org vocabulary to help our customers translate their content to a language understood by search engines.
What Makes Schema.org a Semantic Technology?
Schema.org was founded in 2011 by Google, Bing, Yahoo and Yandex as a way to translate messy human language into structured, machine-readable language. This language is now supported by all major search engines, improving their ability to match search queries with relevant results.
Search engines have shifted to using semantic SEO to provide more accurate and relevant results to users. Instead of matching keywords in an article to search queries, search engines now understand the meaning (semantics) of the content on a page and identify if the content matches the searcher’s intent and query.
In light of this, Schema.org was developed as a vocabulary of types and properties to clearly describe things on a site and provide context on how these things are connected to each other.
Types
The Schema.org types are organized into a hierarchy, starting with Thing and then providing more specific subtypes from there. Example: Thing, which has the subtype Person, which has the subtype Patient.

Properties
Each type has a list of available properties to further describe it. In the image below, we can see that the Person type can be further described with properties like address, alumniOf, and birthDate.
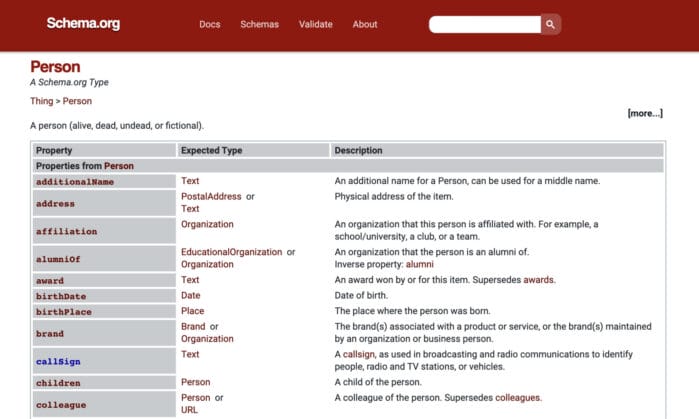
Expected Types for Properties
Most properties also have specific types they can connect to. For example, a Person can have an address property which states the physical address of where the person is located. This information can either be added as plain text, or it can be used to link to the PostalAddress type which has its own page in Schema.org.
By connecting different Schema.org types on your site through the properties, you are defining the relationships between entities described in the content on your site and helping machines understand it.
At Schema App, we apply the Schema.org vocabulary (a loose ontology) to customer content, expressed in JSON-LD (a semantic technology) so that search engines can explicitly understand connections between things (semantics!).
Machine-Readable Representations of Schema.org
Under the hood, the individual terms on the Schema.org website also have ”machine-readable definitions…available as JSON-LD, embedded into the term page[‘s] HTML”.
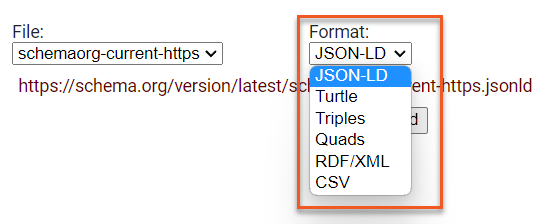
If developers are interested in implementing the vocabulary for their own purposes, Schema.org provides downloadable “Vocabulary Definition Files” available in “common RDF formats” like JSON-LD, Turtle, Triple, or RDF/XML. Here’s a link to what the Schema.org vocabulary looks like as a JSON-LD file.
Schema.org has two interfaces – one for humans to navigate and understand, and another for machines to understand the content within their database. This is a great illustration of how semantic technology works to bridge the gap between human language and machine learning.
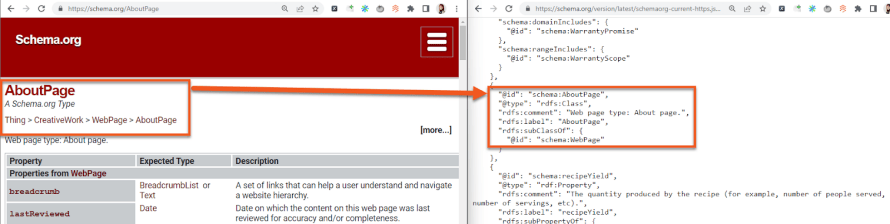
By understanding semantic technologies, companies like Schema App are better able to create applications and systems that leverage the best aspects of these technologies. At Schema App, we use these files in the construction of our authoring tools and implementation of Schema Markup. This allows us to organize customer information in a meaningful way to machines.
Schema App’s expertise in semantic technologies is evident in our numerous tools and features.
Schema App Tools and Features That Make Us Semantic
Here are some of our tools and features that make us semantic.
Schema App Editor & Highlighter
The Schema App Editor and Highlighter are two Schema Markup authoring tools created by our team. The Schema App Editor allows SEO teams to generate Schema Markup in JSON-LD and automatically deploy it to an individual web page without writing a single line of code.
All the pages optimized with Schema Markup can be updated and live on the site in minutes with this tool, making it easy to manage. The Editor contains the entire Schema.org vocabulary and creates connected Schema Markup via embedded data items to allow our customers to build out their knowledge graphs.
The Schema App Highlighter is also a no-code Schema Markup authoring tool, but it is for templated pages and dynamic content rather than individual URLs. With this tool, you can automatically apply descriptive Schema Markup at scale to thousands of pages and dynamically update your Schema Markup based on the content on your page.
What makes our authoring tools semantic?
Both the Editor and the Highlighter have the same semantic features, just applied in a slightly different way.
Using the Schema.org vocabulary
The primary feature that makes our authoring tools semantic is how they author markup using the Schema.org vocabulary to express RDF triples (subject-predicate-object statements) in JSON-LD.
These statements (aka semantic triples) can be combined to create huge graphs of interconnected resources using URIs (Uniform Resource Identifiers). Earlier in the article, we saw a simplified version of the triples. The image below is a more accurate representation of the triples, where the URIs are the entities being described in the graph.

By doing so, they leverage Schema.orgs’ means of translating human-readable content to machine-readable content, supporting the extraction of meaning (semantics) from web content.
All of Schema App’s authoring tools are Ontology-driven applications. Therefore, any updates or modifications to the Schema.org vocabularies will be reflected in the tools. For example, if Schema.org introduces a new property for a specific Type, the new property will be available in Schema App’s authoring tools.
Entity Linking Features
The Highlighter utilizes an automated Linked Entity Recognition feature to identify entities on the page and link them to Google’s knowledge graph and Wikidata definitions, while the Editor employs a manually applied Entity Linking Method. Both tools then nest the entities within the Schema Markup.
By using Entity Linking Methods like Linked Entity Recognition, our authoring tools can help search engines better contextualize the topics on your site and align them with the searcher’s query.
Linked Entity Recognition
As previously stated, Linked Entity Recognition (LER) is a powerful feature that can be applied to a Highlighter template to enhance content analysis.
Once applied, this automated process identifies named entities (such as people, places, things, and concepts) in content. It then links them to external identifiers from authoritative knowledge bases (like Wikipedia and the Google Knowledge Graph). These identifiers are automatically embedded within your Schema Markup.
Through the automatic embedding of these identifiers into the Schema Markup, the entities contribute valuable semantic information to the metadata. Consequently, Google and other web crawlers gain a deeper understanding of the content, thanks to the inclusion of well-defined, linked entities. This reduces ambiguity in the interpretation of content and supports more accurate matching to user queries.
For instance, we can say the DeWalt Handsaw is from the brand DeWalt, which is the same as the DeWalt described in this Wikipedia entity.

By linking the DeWalt Handsaw to the corresponding DeWalt entity on Wikipedia, search engines can clearly understand which DeWalt you are referring to.
Advanced WordPress Plugin
Like our other authoring tools, our Advanced WordPress plugin provides markup using the Schema.org vocabulary. The plugin can automatically generate Schema Markup for pages and posts. It also provides users access to our Schema App Editor for further Schema Markup customizations.
The Advanced WordPress plugin also has the ability to map WordPress tags and categories to Wikipedia and Wikidata entities to help search engines better match content with relevant search queries on those topics.
Schema Paths Tool
The Schema Paths Tool is a free tool created by the Schema App team to help users identify the best way to connect and organize different Schema types together within their Schema Markup. This is especially useful when you’re unsure which properties are available to connect two different Schema.org Types.
The Schema App team identified a need for this within their suite of tools because Schema Markup is most beneficial when it’s highly descriptive. One of the best ways to do this is by connecting your Types with the most descriptive property. The Schema Paths Tool helps you narrow down what properties each Type has that allow them to connect to one another (as an “Expected Type”).
For example, the Schema.org Organization type has more than 50 unique properties. If you want to connect an Organization to a Service it provides, you can enter both Types into the Schema Paths tool, and then receive a list of properties that can be used to connect these Types.

The Semantic Nature of Schema App
By embracing semantic technologies, Schema App helps you develop a reusable knowledge graph which also enables machines to better comprehend and interpret website content. When search engines have a clear understanding of what your page is about, it can provide searchers with more accurate and relevant results.
Our passion for semantic technologies doesn’t end with the tools and features currently available to our users. We pride ourselves on working towards a data-centric architecture for our internal data as well (see Semantic Arts Data-centric architecture manifesto) and invest time considering the possibilities of semantic technology and how we can support them.
Interested in learning more about how our tools can support your semantic SEO initiatives? Get started here.

Jasmine Drudge-Willson is a Product Manager at Schema App. With a background in taxonomy and ontology design, Jasmine applies that experience to the world of Entity SEO, helping structure how machines understand complex business information. Her work focuses on helping marketers grasp the value of knowledge graphs and use entity-driven insights to enhance their search visibility, improve data accuracy, and prepare for AI-driven search.