What is Schema Drift?
Schema drift occurs when schema markup no longer accurately reflects the content on a webpage. It happens when web content changes—whether through updates, site migrations, or evolving SEO strategies—but the structured data remains static, creating a gap between the two.
For example, schema drift can occur when:
- Google Features are introduced and updated
- Schema.org versions change
- Content is published, updated, or moved.
- JavaScript and 3rd party components get updated
- Syndicated content changes structure or content
- CMS switches
- Websites merge, re-architected
- Digital team members change (SEO, Content)
- Companies have mergers and acquisitions, centralize and decentralize
If your schema markup isn’t keeping up with these changes, it can impact search visibility and structured data performance.
Schema drift is a complicated problem that Schema App’s Highlighter resolves. In this article, we’ll define what Schema Drift is, when it tends to happen and how to calculate the magnitude of the issue.
Is Schema Drift a Data Quality problem?
Yes, at its core, schema drift is a data quality problem.
Schema.org markup is a machine-readable representation, a data layer, for content that is presented to human readers. Data Quality, meanwhile, is the measure of how well-suited a data set is to serve its specific purpose. The degree to which the data layer is correct shows up as a data quality problem.
Data Quality is an IT problem with a framework called the Data Management Body of Knowledge (DMBOK) developed over 30 years through a community of experts. DMBOK describes data quality as having the following characteristics:
- Completeness – does the schema data describe the whole content and is it connected to the adjacent data items?
- Validity – Is the schema data correct in its syntax, is it semantically correct as per the schema.org model? Is it valid as per the Google structured data guidelines?
- Accuracy – Degree to which the schema data represents the content
- Consistency – Degree to which the data is equal within and between datasets
- Uniqueness – Degree to which data is unique and cannot be mistaken for other entries
- Timeliness – Degree to which the data is available at the time it is needed
Content-based Schema Drift
Primary schema drift occurs when content on the page is updated but the corresponding schema.org markup does not get updated. This is typical if and when schema.org markup uses static data elements, and users copy/paste content into the schema.

Configuration-based Schema Drift
Inversely, Schema Drift can also occur when the schema.org markup is changed without changes to the schema markup. Perhaps there is a change in mappings, and a setting is changed for a group of pages but accidentally affects the properties of a subgroup of pages. While not intended, the schema markup when variable configurations are used, can be more problematic to detect.
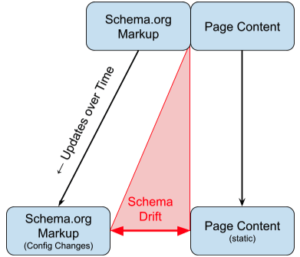
External Schema Drift
A more subtle version of schema drift is when content’s related content changes (connected data items) but that’s not directly observable in the content. External in this case is outside the webpage container, such as other webpages or third party providers.
Example 1: a Physician primary webpage is likely connected to its Service availability, and when the business hours change, the hoursAvailable should also be updated.
Example 2: if an Event is created and the schema markup is correct initially, but the venue changes the Event>location>name or the price went up due to high demand, the Event>offers>price would change. These properties of connected data items may not explicitly be in the page content, but they are certainly relevant and a requirement of the Google feature.
Other times there are 3rd Party plugin providers, e.g. Product Review platforms, which publish schema markup for products without being connected to the rest of the schema markup. While we can use additive schema markup methods with the @id it is brittle and a form of external schema drift.
Schema.org Vocabulary Drift
Terminology Changes
During the year the Schema.org community releases several updates to the vocabulary (https://schema.org/docs/releases.html). During the past few years, there have been several significant changes to terms and the organization of extensions. Each change to the schema.org vocabulary can create Schema Drift. In particular, changes in v0.91 included a large number of properties were made to be singular terms, for example maps became map and members became member. The following shows members is SupersededBy member, telling you if you have the schema.org property, you should update the schema markup.

In the schema.org data model in RDF Graph Database we can retrieve the terms using a simple SPARQL query:
# Find supersededBy terms

| Old term | New term |
| schema:Code | schema:SoftwareSourceCode |
| schema:DatedMoneySpecification | schema:MonetaryAmount |
| schema:Dermatologic | schema:Dermatology |
| schema:Season | schema:CreativeWorkSeason |
| schema:Taxi | schema:TaxiService |
| schema:UserBlocks | schema:InteractionCounter |
| schema:UserCheckins | schema:InteractionCounter |
| schema:UserComments | schema:InteractionCounter |
| schema:UserDownloads | schema:InteractionCounter |
| schema:UserInteraction | schema:InteractionCounter |
| schema:UserLikes | schema:InteractionCounter |
| schema:UserPageVisits | schema:InteractionCounter |
| schema:UserPlays | schema:InteractionCounter |
| schema:UserPlusOnes | schema:InteractionCounter |
| schema:UserTweets | schema:InteractionCounter |
| schema:actors | schema:actor |
| schema:albums | schema:album |
| schema:application | schema:actionApplication |
| schema:area | schema:serviceArea |
Vocabulary is removed
In some vocabulary updates, such as v7.0 there were several largely unused medical terms. If you were a company that used these, you could query a RDF database to look for them.
Removed several largely unused medical health properties whose names were inappropriately general: action, background, cause, cost, function, indication, origin, outcome, overview, phase, population, purpose, source, subtype. Note that we do not remove terms casually, but in the current case the usability consequences of keeping them in the system outweighed the benefits of retaining them, even if flagged as archived/superseded.
Using SPARQL we can query for the list of properties no longer in the vocabulary with
# Find data items using removed properties

Schema.org is versioned but I don’t know that Google supports versioning the markup in the context and I haven’t seen schema.org providers (including us) specify a version of Schema.org that we are implementing.
- Vertical distance is a measure of Time for the number of hours of incorrect schema markup, x
- Horizontal distance is a measure of incorrect properties, in which a simple measure is the number of properties that are no longer correct, y
Drift = x hours * y properties
If you know what day the schema went adrift, then calculate the total area as the risk profile of the drift. If you were to compare that to Google Search Console Indexing API you hope that Google hasn’t indexed it yet.
How might you find Schema Drift on your site?
If and when there is divergence and Schema drift, you should evaluate a page and if the y > 0 you will want to fix the schema markup. Furthermore, you want to address schema drift quickly, and in as little time as possible and ideally before Google indexes it.
Schema Monitoring
Toolkits that monitor your website can and should detect schema drift. Often tools will inform you about what is discovered on the page and potentially what errors/warnings it has. The tools do not understand schema drift, and do not evaluate a comparison of content vs schema markup. At scale, this is a difficult endeavour and why the problem is persistent.
Schema App’s crawler allows you to query the database to see if there are any outdated properties, allowing us to monitor Schema Drift in the vocabulary.
Can I use Microdata & RDFa to avoid schema drift?
Microdata and RDFa are inline HTML tags that directly connect the schema scope and properties to the raw content. Not without their limitations, these syntaxes are no doubt a good way to avoid schema drift. For more complicated graphs of schema content, interlinking data items on the page and across pages can be done with itemref but may point to a broken link or no longer valid items.
Why is Schema Drift important to BI and Data Analytics?
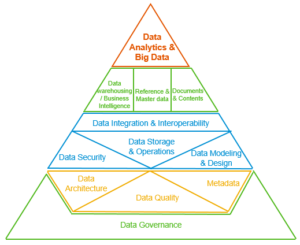
Data Management is the development, execution, and supervision of plans, policies, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their lifecycles. https://dataninjago.com/2021/09/15/what-is-data-management-actually-dama-dmbok-framework/
In the broadest sense, Data Quality is a building block of Data Management. The contribution of the DMBOK pyramid is to reveal the logical progression of steps for constructing a data system. Whether you use this approach or not doesn’t really matter, however data quality is a necessity for building up data analytics projects. If the organization starts to feel the pains from bad data quality, you may need to revisit data quality, have reliable metadata and enforce consistent data architecture.
Ensuring the data quality is fit to use in Phase 2 of the organizations’ data management journey. To ensure the data is of service to higher-order functions, the quality must be relied upon to make decisions. If you’re like some of our customers, schema.org data is supplied not only to Google, but also to other data consumers in the marketing tech stack. Therein, the problem of schema drift and data quality is magnified.
Schema App’s Solution to Schema Drift
Schema App manages Schema Drift through the following solutions.
The Schema App Highlighter is built to dynamically generate schema markup based on the content on the page. So if your teams are changing the content, it is dynamically updated. In addition, if templates within a site are changed, the configuration in Schema App can be updated in minutes.
Schema App Analyzer provides periodic crawls of your website to report on schema data in totality. In addition to validating for Google Features, visualize the results and query the data (RDF triples) for deprecated properties.
Schema App’s dynamic Editor and Highlighter libraries import the latest schema.org vocabulary, mapping old definitions to new ones, so that they are updated dynamically in our customers’ markup.
Lastly, Customer Success at Schema App reviews and resolves errors and warnings, working with our customers to manage content, schema, and component changes.
If you don’t want to worry about Schema Drift, reach out, we’d love to work with you.
Resources & Links
- https://dataninjago.com/2021/09/15/what-is-data-management-actually-dama-dmbok-framework/
- https://www.slideshare.net/alanmcsweeney/data-information-and-knowledge-management-framework-and-the-data-management-book-of-knowledge-dmbok-3366885
- https://www.google.com/search?q=dmbok+data+quality+dimensions
- https://profisee.com/platform/data-quality/
- https://smartbridge.com/data-done-right-6-dimensions-of-data-quality/
- https://www.lean-data.nl/data-quality/

Mark van Berkel is the Chief Technology Officer and Co-founder of Schema App. A veteran in semantic technologies, Mark has a Master of Engineering – Industrial Information Engineering from the University of Toronto, where he helped build a semantic technology application for SAP Research Labs. Today, he dedicates his time to developing products and solutions that help enterprise teams structure and connect their data so it is accurately understood by search engines and AI, improving visibility and enabling more effective AI-driven outcomes.