Generative AI adoption is accelerating, but success depends on having data that AI can actually understand and use. AI-powered tools, from chatbots to automation agents, rely on structured, clean data to deliver meaningful results.
For organizations with Schema.org markup, NLWeb (Natural Language Web) offers a fast, practical way to bridge the gap between your website data and AI applications. In this blog, we’ll provide a high-level overview of NLWeb, its value for enterprise organizations, and the outcomes you can expect from adopting it.
What is NLWeb?
NLWeb is a Microsoft toolkit designed to make AI integration both accessible and cost-effective. It is purpose-built for websites that already use Schema.org markup, making that data immediately usable by AI.
NLWeb allows users to interact with the contents of your site using natural language, much like they would an AI assistant. Instead of relying on rigid keyword search, visitors can ask questions conversationally and receive meaningful, context-aware responses.

The NLWeb interface is intentionally minimal, serving as a blank canvas that can be fully customized to your brand specifications. The default design provided in the toolkit is meant only as a placeholder, giving development teams a starting point to build their own branded experience. What’s more, you can easily adjust the prompts and interactions based on Schema.org Types so the system understands the terms, topics, and goals that matter most for your content.
NLWeb serves as the connective layer that turns structured data into something AI can understand, enabling your website to function as an intelligent, conversational interface.
How NLWeb Works with Schema Markup
NLWeb manages data ingestion, storage, and interaction with large language models (LLMs). The toolkit begins by crawling your site and extracting the schema-marked-up data. Because NLWeb is designed to work with Schema Markup, this is the preferred format. In fact, NLWeb operates by loading JSON-LD formatted Schema.org markup into its MCP server. For cases where your data is not already in this format, such as RSS feeds, NLWeb is able to convert it into JSON-LD using Schema.org types so it can still be ingested and used effectively.
Once collected, this structured data is stored in a vector database. Unlike traditional keyword-based systems, vector databases represent text as mathematical vectors, which allows the AI to search based on meaning and semantic similarity rather than exact keyword matches.
For example, instead of only retrieving results that contain the exact words “Schema Markup,” a vector-based system can also surface articles that use the term “structured data.” While the words are different, the concepts are understood as the same thing in the context of our website content, making the search results more flexible and contextually relevant.
From there, NLWeb connects your structured data to large language models through the Model Context Protocol (MCP). MCP is an emerging standard for packaging and exchanging data so it can be sent, received, and understood consistently by different AI systems. While it is not yet widely adopted, there are currently no real alternatives, which makes MCP the most promising path forward for ensuring interoperability.
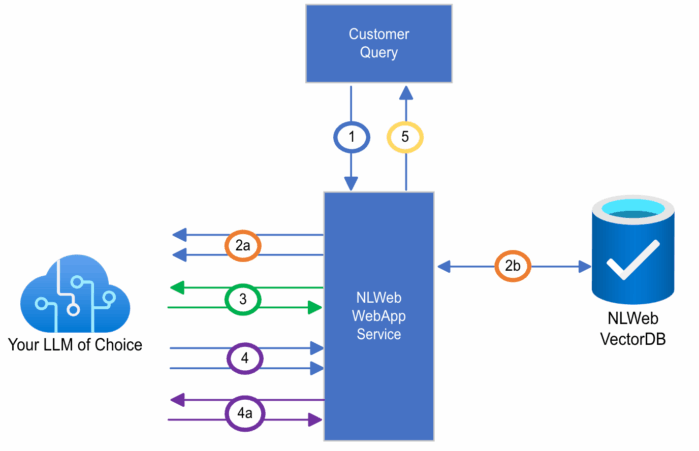
Pictured below is a diagram of how the NLWebApp service works once deployed. The app takes a query [1] and contextualizes that query [2] using multiple parallel calls to the LLM and vector store, utilizing initially requested query types (list, summarize, generate), conversation history, and more. The service may fast-track the query past contextualization [2b] if it is simple and does not need contextualization. The LLM will then select a tool to use [3] based on query contextualization, for example, search, item details, or ensemble queries. The service then takes the results and, again depending on the type of tool selected, compares results [4] and prepares them for display back to the user with optional post-processing [4a].
A helpful way to think about this is like sending a package through the mail: the shipping box represents the standardized MCP format, the contents in the shipping box are your structured data, and the destination is the LLM. NLWeb acts like the post office, ensuring the package is properly addressed, delivered, and returned with the correct information.
To make AI interactions even easier, NLWeb comes with pre-built prompt templates such as “list,” “summarize,” and “generate.” These provide immediate functionality without requiring complex prompt engineering, which can often be time-consuming and difficult to maintain.

The outcome of this process is simple but powerful: with minimal setup, your website data becomes navigable, findable, and usable by AI for a number of use cases across your site.
One of the key reasons Microsoft developed NLWeb is because Schema Markup already exists as a widely adopted way to describe webpages in a structured, contextualized format. As the NLWeb documentation explains:
NLWeb leverages the fact that most such websites already make their data available in a structured form, in a common vocabulary, namely that provided by Schema.org. Given the widespread prevalence of schema.org based markup, it is not surprising that most LLMs seem to understand schema.org markup very well. We exploit this to make it easy to create conversational interfaces.”
Download our report: NLWeb: A Technical Assessment for AI-Enhanced Website Functionality
What is the Outcome You Can Expect From Using NLWeb?
Smarter Search Experience
One of the most immediate benefits of NLWeb is smarter search. Instead of relying on keyword matching, NLWeb enables semantic search that understands the meaning and context behind a query. This means that a search for “Schema Markup” will not only return results with the word in the title but will also uncover related concepts and terms across your site, including blog posts, documentation, and product information.
Improved Content Discoverability
NLWeb also improves content discoverability by surfacing a broader range of content types. Blogs, documentation, landing pages, and other assets are no longer hidden simply because a keyword is missing from the title. By making connections at a semantic level, NLWeb ensures that users can more easily find the most relevant information.
Foundation for AI Use Cases
Beyond search, NLWeb also lays the foundation for advanced AI-driven experiences. It provides the infrastructure needed for building AI-enabled applications such as intelligent chatbots, knowledge assistants, and other customer-facing tools.
With NLWeb, enterprises can move from simple information retrieval to more interactive and context-aware customer experiences.
Why Is It Important for Organizations to Implement NLWeb?
Adopting NLWeb allows organizations to achieve faster time to AI value. Instead of spending months building complex pipelines for AI applications, enterprises can have a proof-of-concept up and running in as little as an hour. This rapid deployment reduces the barriers to experimentation and helps teams demonstrate value quickly.
NLWeb also lowers development costs. Creating a similar solution in-house would require significant engineering resources, specialized expertise, and extensive testing. NLWeb provides these capabilities out of the box, allowing organizations to redirect technical efforts to more strategic initiatives.
Equally important, NLWeb helps future-proof your digital strategy. As AI-driven customer experiences become standard, organizations that are not AI-ready risk falling behind. By leveraging the structured data you already have on your site through Schema Markup, NLWeb enables you to unlock new value without starting from scratch.
The Risk of Not Adopting NLWeb
Organizations that delay adopting NLWeb risk falling behind competitors who are already offering AI-powered search and customer interactions. Continuing to rely solely on keyword-based search will feel increasingly outdated as users come to expect semantic, context-aware results.
Attempting to build custom ingestion and AI integration pipelines in-house often leads to higher costs and slower adoption. In many cases, this also creates technical debt—systems that are expensive to maintain, difficult to scale, and potentially incompatible with future standards like MCP.
NLWeb, by contrast, is designed to be flexible with multiple LLM endpoints, allowing you to switch between models for different use cases as your needs evolve.
The bigger risk is missed opportunities. Without semantic search and AI-driven functionality, enterprises may struggle to deliver the kind of rich, engaging experiences that customers are beginning to expect as the norm.
Strategic Recommendations for Adopting NLWeb
- Enterprises considering NLWeb should begin by using it as a supplementary semantic search tool alongside their existing search. This approach allows you to run A/B tests and gather engagement data before moving into full replacement.
- Once a solid foundation of search and data integration is in place, organizations can expand into more advanced AI applications such as chatbots, knowledge assistants, and automated workflows.
- Partnering with Schema App can help you accelerate this journey, providing expertise in implementation, optimization, and ongoing support. By working with a team that understands both Schema Markup and AI integrations, you can reduce complexity while ensuring your strategy aligns with long-term business goals.
NLWeb Turns Schema Markup into Smarter Customer Experiences
NLWeb makes it possible to operationalize AI on your website quickly, cost-effectively, and strategically by leveraging your existing Schema Markup. It provides enterprises with a scalable path to prepare for the AI-driven future of customer engagement.
Organizations that embrace NLWeb now will be better positioned to deliver:
- Smarter search
- Richer customer interactions
- Ongoing innovation
If you want to explore how NLWeb can be implemented for your enterprise website, get in touch with our team.

Justin Price is a Knowledge Graph Data Scientist at Schema App. With an academic background in the Philosophy of Science, he applies his expertise in semantic data to build and maintain knowledge graph pipelines. His work transforms complex data into actionable insights that help enterprises enhance decision-making and improve data quality at scale.